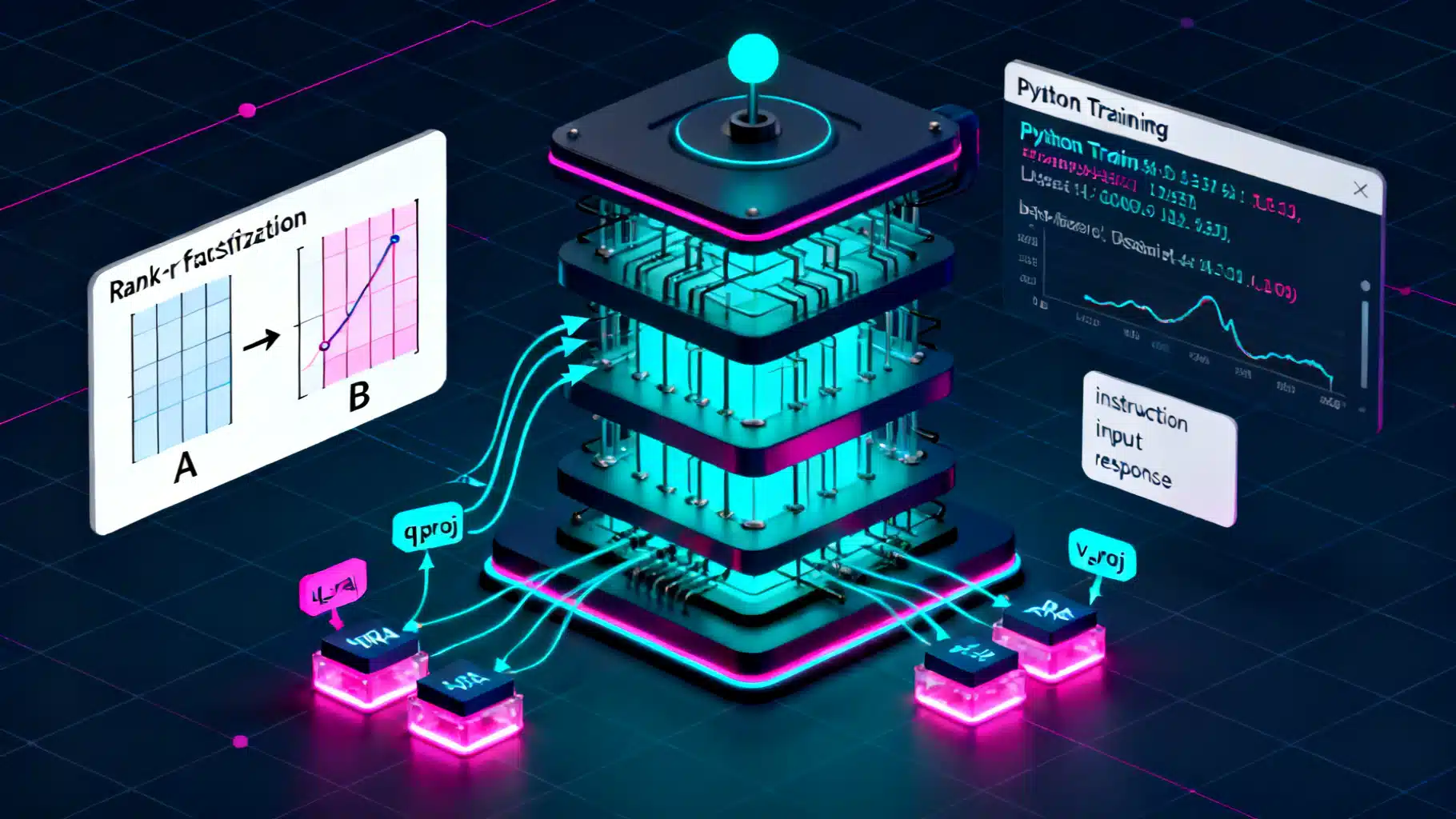
QLoRA Quantized Fine-Tuning: A Practical Guide to Training LLMs on a Single GPU
Step-by-step QLoRA guide with concepts, setup, memory tips, and code to fine-tune LLMs using 4-bit quantization on a single GPU.
ASOasis
Read More
7 min