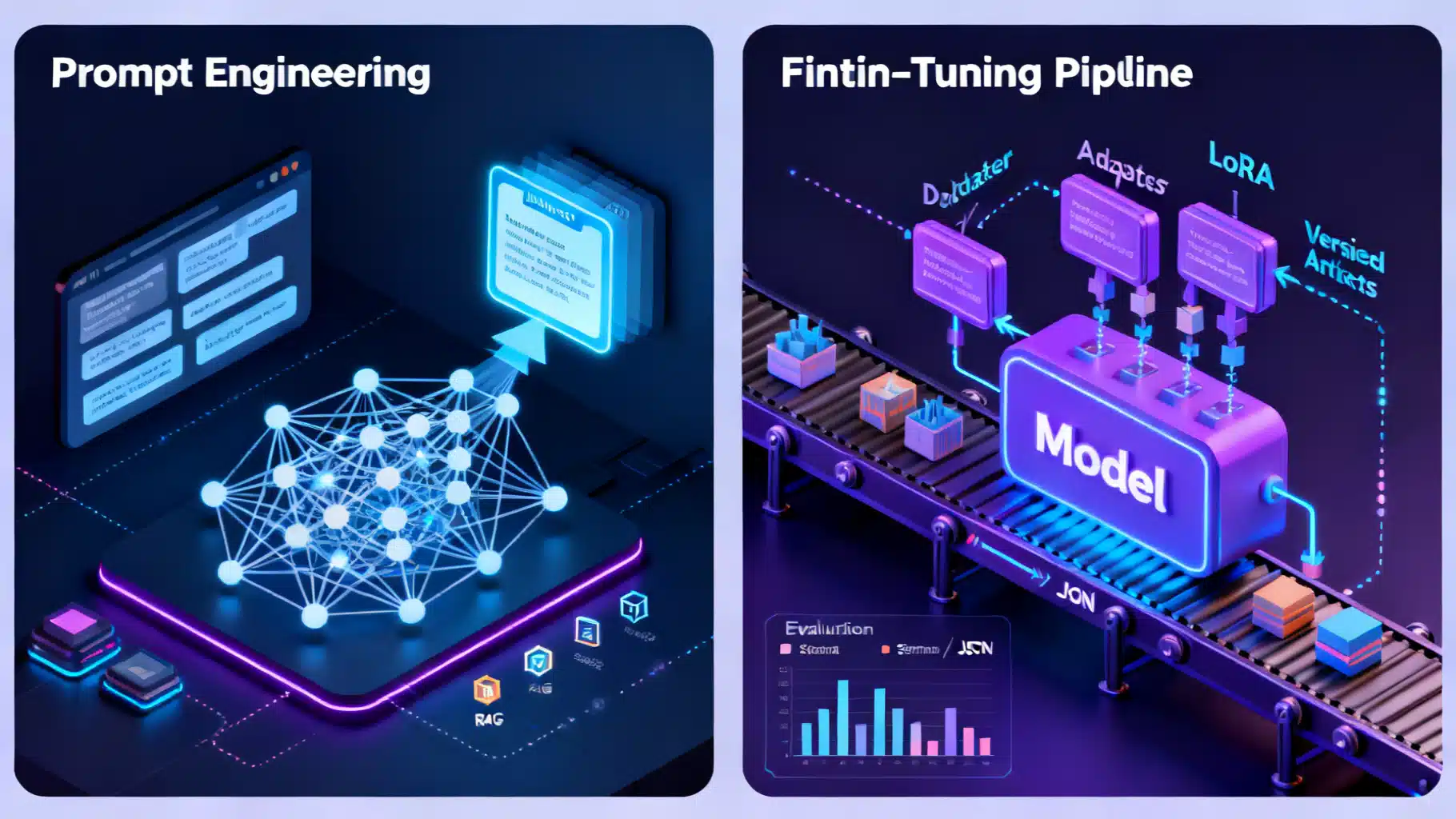
Fine-Tuning vs. Prompting: A Practical Comparison Guide for LLM Teams
A practical, data-driven guide comparing prompting vs. fine-tuning for LLM apps, with decision checklists, trade-offs, and implementation tips.
ASOasis
Read More
7 min